How the Node.js Event Loop works
Node.js is well-known for its non-blocking, event-driven architecture which enables high performance applications that efficiently handle concurrent operations. At the core of this design lies the event loop which is a fundamental mechanism that dictates how asynchronous operations are executed. In this post, we’ll break down the inner workings of the Node.js event loop, flow of phases and how it manages asynchronous tasks.
Node.js Runtime Overview
Node.js is a JavaScript Runtime environment built on Chrome’s V8 engine. It allows JavaScript to run outside the browser. It is asynchronous, event-driven and non-blocking, making it ideal for scalable network applications. The core Node.js Runtime consists of three main components which are
- External dependencies such as V8 Engine, Libuv, Crypto, zlib are on which Node.js relies on for execution.
- C++ bindings act as a bridge between JavaScript and low-level system functionality such as file system access, networking and native modules within Node.js.
- JavaScript libraries (Built-in API & Modules) such as http/https, stream, events, process and worker_threads expose a set of APIs for developers to use.
Introducing the Node.js Event Loop
The event loop is a fundamental concept in Node.js that enables it to perform asynchronous operations and non-blocking operations efficiently. It is the core mechanism that is responsible for managing the execution of code in the event-driven environment. The event loop is a core part of Libuv, a C library that provides asynchronous I/O handling and a cross-platform abstraction for event-driven programming.
Node.js operates on a single-threaded event loop but it uses Libuv to delegate the expensive tasks such as file I/O, networking to the operating system or a thread pool. So, understanding the Node.js event loop is important to build scalable backend applications especially when dealing with intensive input/output bound tasks such as file reading, making network requests and handling multiple client connections concurrently.
For further understanding, let’s create a file named blocking.js for the demonstration of blocking the event loop.
function blockingOperation() {
console.log("Start blocking operation");
for (let i = 0; i < 1000000000; i++) {
// This loop will keep the CPU busy for a while,
// blocking other operations
}
console.log("End blocking operation");
}
console.log("Before blocking operation");
blockingOperation();
console.log("After blocking operation");In the above example, it performs a blocking operation by using a synchronous loop that keeps the CPU busy. When running the script, it will log Before blocking operation, executes the blockingOperation function with its intensive blocking loop and finally After blocking operation. This kind of CPU-intensive task should be offloaded to Worker Threads or child processes to avoid blocking the event loop.
Now, let’s demonstrate a non-blocking operation and create a file called non-blocking.js.
console.log("Before non-blocking operation");
setTimeout(() => {
console.log("Non-blocking operation completed");
}, 2000);
console.log("After non-blocking operation");This example performs a non-blocking operation using the setTimeout() function which will execute after 2 seconds. When running the script, it will log Before non-blocking operation, schedules the timeout, immediately log After non-blocking operation. After 2 seconds, it logs Non-blocking operation completed. As an example, Node.js remains responsive and continue the other tasks. setTimeout() is executed in the timers phase of the event loop, ensuring the main thread remains free to process other tasks in the meantime.
How does it work?
Node.js operates on a single-threaded environment which means it uses a single main thread for the execution of JavaScript Code. However, it can still handle many concurrent operations by leveraging asynchronous and non-blocking I/O. Node.js is event-driven which means it relies on events and callbacks in order to execute code for the response of various actions or events. Events can be I/O operations, timers, custom events triggered by the code.
These are four key mechanisms to understand how Node.js handles I/O operations.
- Non-Blocking I/O: Node.js doesn’t wait for each operation to complete before moving on which is known as non-blocking I/O. It can handle multiple tasks concurrently, making it highly efficient for I/O heavy operations such as file reading, network requests and database queries.
- Event Queue (Task Queue): When an asynchronous operation is triggered, Node.js doesn’t block the entire program. Instead, it puts these operations in a queue called the Event Queue and continues with other tasks.
- Event Loop: The Event Loop continuously checks the Event Queue and executes the pending tasks. If there’s an operation in the queue that has been completed, the Event Loop executes its associated callback function in the appropriate phase. This mechanism ensures smooth execution without blocking the main thread.
- Callback Functions: When an asynchronous operation is initialized, it is typically associated with a callback function. Once the operation completes, the callback is executed to handle the result.
Flow of Phases
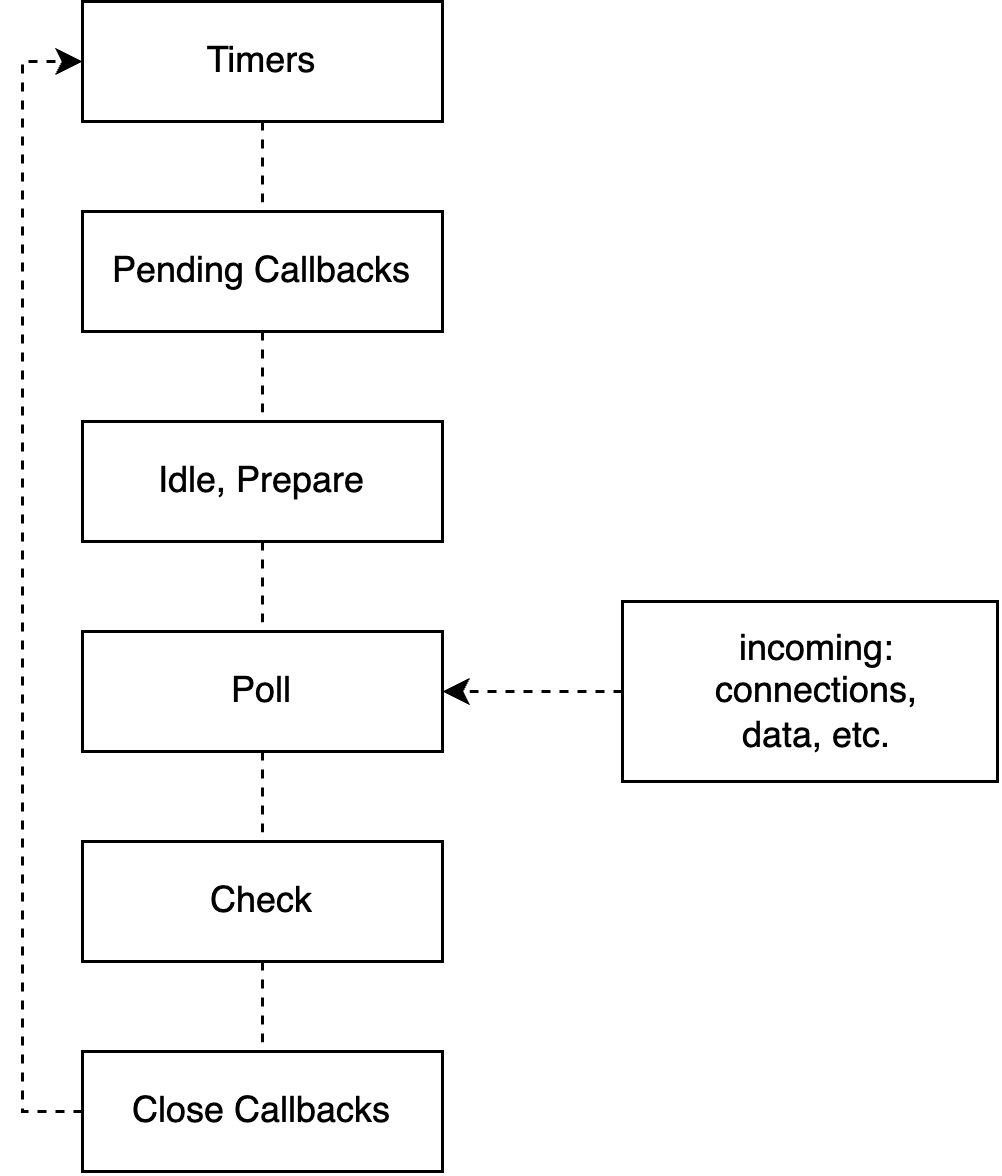
The Event Loop operates a flow of phases. It is essential to understand these phases when debugging, optimizing performance and working with Node.js’s non-blocking behavior. When the Node.js process starts, the Event Loop is initialized and continues through these phases:
- Timers Phase: This phase checks for any scheduled timers that need to be executed. These timers are typically created using functions such as setTimeout() and setInterval(). If a timer’s specific time has passed, its callback function is added to the I/O polling phase.
- Pending Callbacks Phase: In this phase, the event loop checks for events that have completed or errored their I/O operations. If any operations have been completed, their associated callback functions are executed during this phase.
- Idle, Prepare Phase: These phases are rarely used in typical application development. These are only used internally and are reserved for special use cases. The idle phase runs callbacks that are scheduled to execute during the idle period while the prepare phase is used to prepare for poll events.
- Poll Phase: This phase is where most of the actions happen in the event loop. It performs the following tasks:
- It checks for new I/O events and executes callbacks if any of them are ready.
- If I/O events are not pending, it checks the callback queue for pending callbacks that are scheduled by timers or setImmediate(). If any are found, they are executed.
- If there are no pending I/O events or callbacks, the event loop will wait for new events to arrive in an efficient, non-blocking manner. This is called “Polling”.
- Check Phase: In this phase, callbacks registered with setImmediate() are executed. These callbacks run immediately after the current poll phase completes but before any timers are checked again.
- Close Callbacks Phase: The close event will be emitted in this phase. It is responsible for executing close event callbacks such as socket.destroy().
After completing all these phases, the event loop checks if there are any pending timers, I/O operations or other events. If there are, it goes back to the appropriate phase to handle them. Otherwise, if there are no further pending events, the Node.js process ends.
By efficiently managing timers, I/O tasks, and callbacks, the event loop allows Node.js to handle thousands of concurrent connections without blocking the main thread, making it ideal for high-performance network applications. Understanding the phases of the event loop is crucial for optimizing performance, avoiding bottlenecks, and writing scalable applications. Leveraging non-blocking I/O and asynchronous programming principles ensures that Node.js applications remain fast and responsive even under heavy loads.